
Selenium WebDriver
Introdução
O Selenium WebDriver é uma API orientada a objetos que permite manipular um navegador como um usuário faria, ou seja, o Selenium WebDriver permite automatizar a interação que existe entre o usuário e o navegador escolhido.
Alguns passos deve ser executados para que o Python possa controlar um navegador usando o Selenium WebDriver: primeiro é criado um driver (motorista) para um navegador (Chrome, Firefox, etc); em seguida o Python solicita que o driver abra uma determinada página HTML no navegador escolhido; o navegador carrega a página e gera o DOM correspondente; agora o Python pode acessar os elementos HTML da página para coletar dados e/ou executar ações.
Métodos
O WebDriver é o módulo do Selenium que provê implementações para diferentes navegadores como Firefox, Chrome e Safari. São exemplos de métodos do WebDriver:
- close() – fecha a janela corrente do navegador;
- quit() – fecha o navegador e todas as janelas abertas;
- forward() – move para a página seguinte no histórico do navegador;
- back() – move para a página anterior no histórico do navegador;
- execute_script() – executa um script JavaScript;
- maximize_window() – maximiza o tamanho da janela do navegador;
- minimize_window() – minimiza o tamanho da janela do navegador.
O Selenium WebDriver fornece métodos para localizar elementos HTML em uma página usando o DOM. O método find_element() retorna o primeiro elemento encontrado para a especificação dada. O método find_elements() retorna a lista com todos os elementos encontrados na página com a especificação. É preciso importar a classe By para que esses dois métodos funcionem.
from selenium.webdriver.common.by import By
As várias estratégias disponíveis para localizar um elemento HTML são mostradas a seguir. A página oficial do Python foi usada para extrair os exemplos.
- Identidade do elemento – usa a identidade (id) para localizar um elemento HTML. O correto é que as identidades sejam únicas (sem repetição) no documento, assim, a lista deverá ter um único elemento. Para achar a lista de elementos com identidade igual a “homepage“, use
elementos = driver.find_elements(By.ID, "homepage")
- Nome do elemento – procura pelo valor do atributo “name”. Elementos diferentes devem ter nomes diferentes. Para localizar o primeiro elemento (espera-se que seja o único) com nome “submit“, entre com
elemento = driver.find_element(By.NAME, "submit")
- Nome da classe – usa o nome da classe para localizar um elemento. Para procurar pelo primeiro elemento da página que tem classe “menu“, basta usar
elemento = driver.find_element(By.CLASS_NAME, "menu")
- Texto dos links – para fazer uma lista de todos os links cujo texto (aparece para o usuário) é “Success Stories“, use
elementos = driver.find_elements(By.LINK_TEXT, "Success Stories")
- Texto parcial dos links – para localizar o primeiro link cujo texto possui a substring “Stories“, basta usar
elemento = driver.find_element(By.PARTIAL_LINK_TEXT, "Stories")
- Nome da tag (etiqueta do HTML) – para selecionar todos os parágrafos de uma página, entre com
elementos = driver.find_elements(By.TAG_NAME, "p")
- Seletor de CSS – serve para combinar um seletor de elemento e um valor de seletor que identifica o elemento em uma página. Para localizar um seletor “input” com id igual a “id-search-field“, use
elemento = driver.find_element(By.CSS_SELECTOR, "input[id=id-search-field]")
- Linguagem XPATH (XML Path Language) – permite identificar nós em um documento XML/HTML e suporta métodos simples de localização por atributo, id e nome. Para localizar os links com o atributo aria-hidden (oculta conteúdo não interativo da API de acessibilidade), basta entrar com
elementos = driver.find_elements(By.XPATH, '//a[@aria-hidden]')
São exemplos de métodos do Selenium que podem ser usados com os elementos HTML localizados na página:
- is_selected() – retorna True se o elementos de uma caixa de seleção tiver sido selecionado;
- is_displayed() – retorna True se o elemento estiver visível;
- is_enabled() – retorna True se o elemento estiver habilitado;
- clear() – limpa o texto digitado no elemento;
- get_property() – fornece informações sobre as propriedades do elemento;
- get_attribute() – fornece informações sobre os atributos do elemento;
- click() – clica no elemento;
- submit() – submete um formulário.
São exemplos de métodos do Selenium disponíveis para os elementos HTML:
- tag_name – o nome da tag (etiqueta HTML);
- text – o texto do elemento (aparece para o úsuário na página);
- title – título da página.
Exemplos
- Exemplo: o programa abre a página inicial do Python no Firefox, coloca “getting started with python” no campo de busca e tecla ENTER.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.set_window_size(1920, 1080)
driver.get("https://www.python.org")
print(driver.title)
search_bar = driver.find_element(By.NAME, "q")
search_bar.clear()
search_bar.send_keys("getting started with python")
search_bar.send_keys(Keys.RETURN)
print(driver.current_url)
A tela abaixo é mostrada ao final da execução.
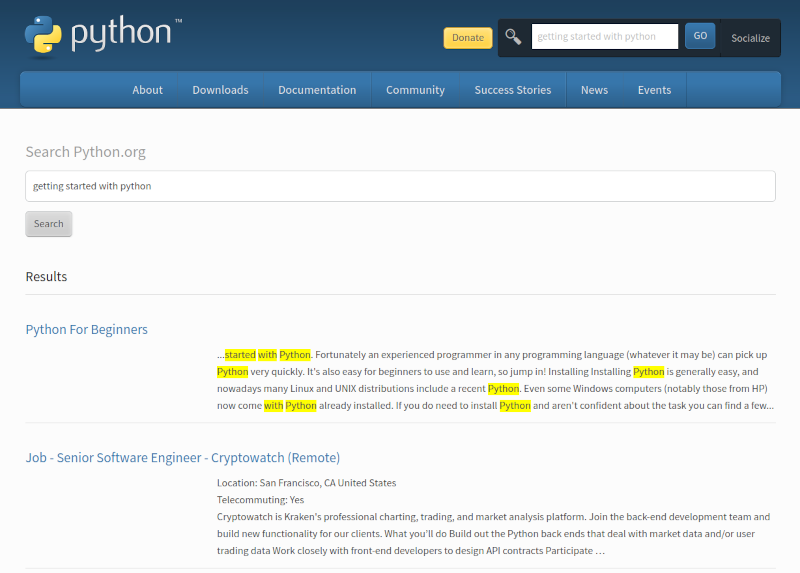
O campo de pesquisa da página Python tem as definições mostradas abaixo. Note que o nome do campo é ‘”q”.

Veja https://www.selenium.dev/selenium/docs/api/py/webdriver/selenium.webdriver.common.keys.html para a lista de chaves (keys) que podem ser usadas com o Selenium.
Se quiser usar um arquivo HTML que está no seu computador no teste, basta fornecer o caminho absoluto do arquivo. Por exemplo,
driver.get('file:///home/aluno/Área de Trabalho/Python/python.html')
usa o arquivo “python.html” que se encontra em “/home/aluno/Área de Trabalho/Python/”.
- Exemplo: o script acessa o Google, escreve “unirio” no campo de pesquisa e pressiona o botão “Estou com sorte”.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("https://www.google.com.br/")
search_bar = driver.find_element(By.NAME, "q")
search_bar.clear()
search_bar.send_keys("unirio")
driver.execute_script("document.getElementsByName('btnI')[0].click();")
Ao final da execução, a página da UNIRIO é apresentada.

O método execute_script() executa um script JavaScript no programa Python. Neste caso, todos os elementos com nome “btnI” são selecionados, mas apenas o primeiro botão (index [0]) é clicado. Abaixo a definição do botão “Estou com sorte”.

- Exemplo: o programa usa duas opções do Selenium para o Firefox. A primeira opção (headless) define que a interface gráfica do navegador não será utilizada (o navegador é executado em background). A segunda opção (log.level) habilita o log no nível “trace” durante a execução dos comandos (este é o nível mais completo do log, pois fornece informações sobre depuração, configuração, advertências, etc); o log é gravado no arquivo geckodriver (utilizado para realização de testes de softwareo com o Firefox). Note que o código-fonte da página do Python é mostrado no final do programa.
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
opts = Options()
opts.headless = True
opts.log.level = "trace"
driver = Firefox(options=opts)
driver.get('https://www.python.org')
content = driver.page_source
print(content)
- Exemplo: é similar ao exemplo anterior, só que usando o navegador Chrome. Além disso, ao invés de mostrar todo o código-fonte da página, lista apenas os parágrafos.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
opcoes = webdriver.ChromeOptions()
opcoes.headless = True
driver = webdriver.Chrome(options=opcoes)
try:
driver.get('https://www.python.org')
paragrafos = driver.find_elements(By.TAG_NAME, "p")
for parag in paragrafos:
print(parag.text)
finally:
print("\n*** Fim da execução")
- Exemplo: o script pesquisa links com texto “Documentation” na página oficial do Python.
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
opts = Options()
opts.headless = True
driver = Firefox(options=opts)
try:
driver.get('https://www.python.org')
links = driver.find_elements(By.LINK_TEXT, "Documentation")
for link in links:
print(link.text)
finally:
print("\n*** Fim da execução")
Dois links com texto “Documentation” são encontrados.
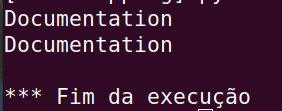
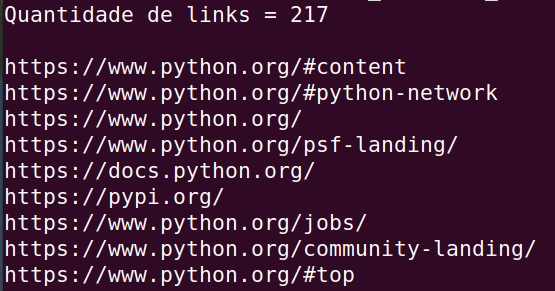
- Exemplo: lista todos os valores do atributo “href” dos links da página do Python.
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
opts = Options()
opts.headless = True
driver = Firefox(options=opts)
driver.get('https://www.python.org')
links = driver.find_elements(By.TAG_NAME, 'a')
print("Quantidade de links =", len(links), "\n")
i = 0
for link in links:
print(links[i].get_attribute('href'))
i = i + 1
A parte inicial da resposta do programa é mostrada abaixo.
- Exemplo: o programa lista os links que têm atributo “href” (note a semelhança com o programa do exemplo anterior). O uso da linguagem XPATH permite definir que a procura é por nós âncoras (‘//a’) que possuem atributos href (‘[@href]’).
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
opts = Options()
opts.headless = True
driver = Firefox(options=opts)
driver.get('https://www.python.org')
links = driver.find_elements(By.XPATH, '//a[@href]')
print("Número de links: " + str(len(links)) + "\n")
for link in links:
print(link.get_attribute('href'))
- Exemplo: o script abre uma nova instância do Firefox (mesmo que o navegador já esteja em uso) e exibe a página oficial do Python; em seguida abre uma nova aba, na instância criada, e exibe a página com documentações do Python; no final, volta à primeira aba que passa a exibir a página de notícias do Python.
from selenium import webdriver
driver=webdriver.Firefox()
driver.get("https://www.python.org")
driver.execute_script("window.open()")
driver.switch_to.window(driver.window_handles[1])
driver.get("https://www.python.org/doc/")
driver.switch_to.window(driver.window_handles[0])
driver.get("https://www.python.org/blogs/")
- Exemplo: Acessa o submenu “FAQ” que se encontra no menu “Documentation” da página inicial do Python. Na nova página clica em “General Python FAQ“. Note que a classe “ActionChains” é usada na execução das duas primeiras ações. Esta classe permite enfileirar ações a serem executadas. Assim, o Selenium move para o item ““Documentation” do menu, o menu abre as opções e o item “FAQ” é selecionado. Uma pausa de 3 segundos é feita para permitir o carregamento da segunda página antes da seleção do link “General Python FAQ“.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
opcoes = webdriver.ChromeOptions()
#opcoes.headless = True
driver = webdriver.Chrome(options=opcoes)
driver.get("https://www.python.org/")
acao1 = driver.find_element(By.LINK_TEXT, "Documentation")
acao2 = driver.find_element(By.LINK_TEXT, "FAQ")
grupo = ActionChains(driver)
grupo.move_to_element(acao1)
grupo.click(acao2)
grupo.pause(3)
grupo.perform()
driver.find_element(By.LINK_TEXT, "General Python FAQ").click()
Além do método “pause()” da classe “ActionChains“, existem outras formas de sincronizar ações e resultados no Selenium WebDriver.
- Usar o método “sleep()” da classe “time” – Neste caso basta importar a classe (“import time“) e chamar o método quando necessário. Por exemplo, para fazer o programa “dormir” por três segundo em algum ponto da execução, use o comando “time.sleep(3)“. Este comando permite definir uma espera explícita estática (static explicit wait).
- Usar o método “until()” da classe “WebDriverWait” para definir até quando se deve esperar por um evento. Por exemplo, “WebDriverWait(driver, 3).until(EC.presence_of_element_located((By.LINK_TEXT, “General Python FAQ”))).click()” espera até três segundos para que o elemento com texto de link igual a “General Python FAQ” seja encontrado na página (a nova página pode demorar a ser carregada). Este comando define uma espera explícita dinâmica (dynamic explicit wait) para um determinado comando. Para este exemplo, é preciso importar dois módulos: “from selenium.webdriver.support import expected_conditions as EC” e “from selenium.webdriver.support.ui import WebDriverWait as EC“.
- Usar o método “implicitly_wait()” do WebDriver para garantir um tempo de espera para os comandos “find_element“. Por exemplo, o comando “implicitly_wait(3)” faz com que o objeto WebDriver tente encontrar os elementos da página por até três segundos. Isto significa que página será verificada várias vezes por até três segundos. Se o elemento é encontrado, o programa continua a execução normalmente. Se o elemento não é achado durante três segundos, uma exceção é gerada. Note que o valor definido no comando “implicitly_wait()” é usado em todas as pesquisas feitas pelo WebDriver. O valor padrão de espera por um elemento é zero.