
Exemplos
Alguns exemplos, apresentados nesta página, foram feitos pelos alunos do BSI na disciplina que trabalhou com raspagem de dados.
- Exemplo: O objetivo de um programa Web Scraper é fazer um rastreamento exaustivo de um site. Ele começa com uma página de nível superior e pesquisa todos os links internos do site. Este tipo de programa pode coletar informações para:
- Gerar um mapa do site – rastrear links internos, seções, organizações das páginas, etc
- Coletar dados – fazer uma pesquisa especializada (criar rastreadores que percorrem recursivamente um site e coletar apenas os dados encontrados nas páginas)
O programa apresentado a seguir é um Web Scraper para o site oficial do Python. Dois arquivos são gravados: o “arq_urls.txt” com os links das páginas do site que não tiveram problemas ao fazer conexão (exceto objetos pdf e png); e o “arq_erro.txt” com os links que deram erro ao tentar a conexão.
from bs4 import BeautifulSoup as bs
import requests, re
paginas = set()
arq_urls = open("arq_urls.txt","w")
arq_erro = open("arq_erro.txt", "w")
def getLinks(URL):
global paginas
try:
PagAtual = requests.get(URL)
except Exception as erro:
arq_erro.write(URL + "\n")
arq_erro.write(str(erro) + "\n\n")
arq_erro.flush()
else:
arq_urls.write(URL + "\n")
arq_urls.flush()
resposta = bs(PagAtual.text, 'html.parser')
for link in resposta.findAll("a", href=re.compile(r'python\.org')):
NovaPagina = link.attrs['href']
pdf = re.search(".pdf", NovaPagina)
png = re.search(".png", NovaPagina)
if not pdf and not png:
if NovaPagina not in paginas:
paginas.add(NovaPagina)
getLinks(NovaPagina)
getLinks("https://www.python.org/")
arq_urls.close()
arq_erro.close()
As primeiras linhas do arquivo “arq_urls.txt”:
https://www.python.org/ https://docs.python.org https://www.python.org/ https://docs.python.org/3/license.html https://www.python.org/psf/ https://www.python.org/psf/donations/matching-gifts/ https://wiki.python.org/moin/BeginnersGuide
As primeiras linhas do arquivo “arq_erro.txt”:
//devguide.python.org/_/downloads/en/latest/htmlzip/ Invalid URL '//devguide.python.org/_/downloads/en/latest/htmlzip/': No scheme supplied. Perhaps you meant http:////devguide.python.org/_/down loads/en/latest/htmlzip/? //devguide.python.org/_/downloads/en/latest/epub/ Invalid URL '//devguide.python.org/_/downloads/en/latest/epub/': No scheme supplied. Perhaps you meant http:////devguide.python.org/_/downloa ds/en/latest/epub/? mailto:python-dev@python.org No connection adapters were found for 'mailto:python-dev@python.org'
- Exemplo: o script acessa o site do Portal da Transparência e extrai os dados de 2021 das duas tabelas que aparecem no início da página do Ministério da Educação.
#
# Projeto Final - Orçamento do MEC e Universidades Públicas Federais
## Aluno: Matheus Zaiat C. Gomes (20182210007)
## Bacharelado em Sistemas de Informação - UNIRIO (RJ)
#
import requests
import bs4
import csv
headers = {'User-agent': 'Mozilla/5.0'}
site = 'https://www.portaltransparencia.gov.br/orgaos-superiores/26000?ano=2021' # ano de 2021
r = requests.get(site, headers=headers)
pagina = bs4.BeautifulSoup(r.content, "html.parser", from_encoding='utf-8')
# Captura as despesas totais (primeira tabela)
# Grava no arquivo "pagamentos.csv"
tabela = pagina.findAll("table")[0]
celulas = tabela.findAll(['td', 'th'])
with open("pagamentos.csv", "wt+", newline="") as f:
writer = csv.writer(f, delimiter = ";")
csv_linha = []
for celula in celulas:
csv_linha.append(celula.text)
writer.writerow(csv_linha)
writer.writerow("")
# Captura a distribuição dos pagamentos (segunda tabela)
# Grava no arquivo "pagamentos.csv"
tabela = pagina.findAll("table")[1]
linhas = tabela.findAll("tr")
with open("pagamentos.csv", "at+", newline="") as f:
writer = csv.writer(f, delimiter = ";")
for linha in linhas:
csv_linha = []
for cell in linha.findAll(["td", "th"]):
csv_linha.append(cell.get_text()) # colocando cada célula na linha do arquivo
writer.writerow(csv_linha)
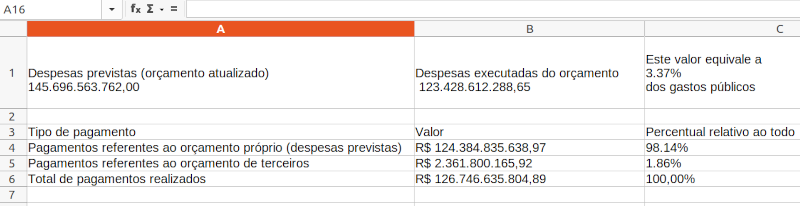
O arquivo “pagamentos.csv” possui o seguinte conteúdo:
" Despesas previstas (orçamento atualizado) 145.696.563.762,00 ";" Despesas executadas do orçamento 123.428.612.288,65 ";" Este valor equivale a 3.37% dos gastos públicos " Tipo de pagamento;Valor;Percentual relativo ao todo Pagamentos referentes ao orçamento próprio (despesas previstas);R$ 124.384.835.638,97;98.14% Pagamentos referentes ao orçamento de terceiros;R$ 2.361.800.165,92;1.86% Total de pagamentos realizados;R$ 126.746.635.804,89;100,00%
Acessando o arquivo com uma planilha, pode-se ver:
- Exemplo: o programa abaixo fornece as emendas parlamentares de um determinado ano para uma Universidade Pública Federal. Os dados são extraídos do Portal da Transparência. Por exemplo, para obter as emendas parlamentares da UNIRIO (Órgão 26269) no ano de 2018, salve o código abaixo como emendas.py e digite na linha de comandos:
python emendas.py 2018 26269
#
# Projeto Final - Emendas Parlamentares das Universidades Públicas Federais
## Aluna: Laryssa Castro Rangel (20181210010)
## Bacharelado em Sistemas de Informação - UNIRIO (RJ)
#
from numpy import ScalarType
from pandas.core.arrays.categorical import contains
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options as FirefoxOptions
import requests
import pandas as pd
import time
import sys
# Códigos das Universidades Públicas Federais
universidades = [26230, 26231, 26232, 26233, 26234, 26235, 26236, 26237, 26238, 26239,
26240, 26241, 26242, 26243, 26244, 26245, 26246, 26247, 26248, 26249,
26250, 26251, 26252, 26253, 26254, 26255, 26258,
26260, 26261, 26262, 26263, 26264, 26266, 26267, 26268, 26269,
26270, 26271, 26272, 26273, 26274, 26275, 26276, 26277, 26278, 26279,
26280, 26281, 26282, 26283, 26284, 26285, 26286,
26350, 26351, 26352, 26440, 26441, 26442, 26447]
if len(sys.argv) < 3:
print("Forneça o ano com 4 dígitos e o código do órgão")
else:
ano = int(sys.argv[1])
orgao = int(sys.argv[2])
from datetime import date
data_atual = date.today()
ano_atual = data_atual.year
if ano > ano_atual:
print("Ano deve ser menor que", ano_atual + 1)
quit()
if orgao not in universidades:
print("Órgão não é de uma Universidade Pública Federal:", orgao)
quit()
options = FirefoxOptions()
options.add_argument("--headless") #Realiza o teste sem abrir a janela do navegador
driver = webdriver.Firefox(options=options)
url_pesq = "http://www.portaltransparencia.gov.br/despesas/orgao/consulta?paginacaoSimples=true&tamanhoPagina=&offset=&direcaoOrdenacao=asc&de=01%2F01%2F" + str(ano) + "&ate=31%2F12%2F" + str(ano) + "&orgaos=OR" + str(orgao) + "&localidadeGasto=ET19&planoOrcamentario=8600018&colunasSelecionadas=mesAno%2CorgaoVinculado%2CunidadeGestora%2Cprograma%2Cacao%2Cautor%2CgrupoDespesa%2CvalorDespesaEmpenhada%2CvalorDespesaLiquidada%2CvalorDespesaPaga%2CvalorRestoPago"
def lista_emendas(url):
driver.get(url)
#Utilizando o pandas, cria um dataframe vazio
df_final = pd.DataFrame()
while True:
# Tempo para carregar a página para que as informações da tabela apareçam
time.sleep(2)
# Identifica a classe que determina existência de próxima página
next_page_btn = driver.find_elements(By.XPATH, "//li[@class = 'paginate_button next']/a")
# Mostra todo o conteúdo da tabela
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
# Busca a tabela
element = driver.find_element(By.XPATH, '//*[@id="lista"]')
# Pega o conteúdo html da tabela
html_content = element.get_attribute('outerHTML')
# Extrai o conteúdo da tabela sem tags HTML
df_full = pd.read_html( str(html_content))[0]
# Adiciona a tabela da página ao dataframe
df_final = df_final.append(df_full, ignore_index = True)
# Se não houver mais próxima página, interromper
if len(next_page_btn) < 1:
break
else:
# Clica no botão que leva para a próxima página
driver.find_element(By.ID, 'lista_next').click()
driver.quit()
return df_final
# Gera um arquivo csv com as listas
nome = "emendas" + str(ano) + ".csv"
arq = open(nome, "w")
lista_emendas(url_pesq).to_csv(arq, index=False, encoding="utf-8", sep=';')
arq.close()
As primeiras linhas do arquivo CSV são mostradas abaixo.

O arquivo aberto pela planilha corresponde à figura abaixo.
